Routing and firewalling for a home network
Running a dedicated routing firewall at home may look complicated, but it really isn't. Unfortunately, the details are spread among various places. This is kind of a walkthrough for those with basic knowledge of Linux and networking, showing how to build a simple routing firewall for a typical small home network like my own: A couple servers, some Linux and Windows workstations, printer, webcam and stuff filling that 24-port switch for some reason. I do not give a complete configuration, which had to be adapted to your system anyway, but point out the vital parts and how things play together.
LAN connectivity
Here is the first thing to configure: The LAN interface. I use multiple VLANs for switches, servers, workstations, Windows and "stuff that needs a port". By using VLAN-tagging on the way to the router, I save physical ports. First, enable the interface:
ip link set dev eth1 up
Now add virtual VLAN-tagged interfaces and assign networks to them, like shown for the first VLAN:
ip link add link eth0 name eth1.1 type vlan id 1
ip link set eth1.1 up
ip -f inet addr add 10.127.0.1/24 broadcast 10.127.0.255 dev eth1.1
And so on for all other VLANs. That way the broadcast domains are kept small and firewalling things nicely is easy. You can use 4095 VLANs, that's more than enough for home.
Access connectivity
Like many, I got a T-DSL line, but almost every fast line for consumers offers at most a dynamic IP, if not just crippled (NAT or filtered) access. That's the price you pay for cheap access and the constant change of offers and features means selecting a specific offer to save the hassle won't do the job for long (tried). A constructive approach helps and whining does not, so I react by separating basic access and static IP routing using a tunnel. That way I am flexible to change access, if needed.
Now let's get to the access connection. At first, the Ethernet link to the DSL modem should be up:
ip link set eth0 up
Most modern modems can be managed and have a pre-configured IP for that. My modem listens on 192.168.1.1, so I configure a /24 and set my IP in its middle, which is unlikely to be used by future modems:
ip -f inet addr add 192.168.1.127/24 dev eth0
Now that the modem can be reached and the line is up, let's
move on to internet connectivity. I want to use
ppp0 and apart from the standard PPPoE configuration, my
/etc/ppp/peers/tdsl-tonline file contains the following lines.
The first logs the PPP configuration frames to recognize mistakes and
sets a unique prefix for logfile and configuration:
debug
logfile /etc/ppp/peers/tdsl-tonline.log
ipparam tdsl-tonline
This configures the underlying Ethernet interface and sets the PPP interface number:
local
eth0
unit 0
user '<Anschlusskennung><T-Online Nummer>#0001@t-online.de'
noipdefault
Finally, this group will create a new connection if it is closed:
persist
maxfail 0
holdoff 6
lcp-echo-interval 10
lcp-echo-failure 4
You may notice that there is no defaultroute
configured. That's right, I'll come back to that soon.
Back then, I used multi session PPPoE with a second interface to terminate statically routed traffic, but that option was canceled. As I said, it was not too smart to rely on specific access features.
Now I have a system with connections to multiple LANs and access connectivity, but no static IP yet.
Statically routed access connectivity
Among the various tunnel protocols, openvpn is particularly easy to set up and many commercial offers come with finished configurations. Using multiple interfaces, I want them to be persistent to avoid conflicts:
ip tuntap add dev tun0 mode tun
Just make sure not to get a default route pushed or reject it, if needed.
For IPv6, I need to assign the link local address manually on tun0
using the up script:
ip -6 addr add fe80::ffff/64 dev $1
If you can ping the peer, static IP connectivity is fine. Now, how to decide when to use which route?
Setting up routing
First enable routing at all and for all interfaces:
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/conf/default/forwarding
echo 1 > /proc/sys/net/ipv4/conf/all/forwarding
The wish to route packets belonging to certain network services differently than others is commonly called "policy routing", but "advanced routing" in Linux. Instead of a single routing table, you have multiple tables, and a new table of rules to select which routing table to use. Packets not routed by one table fall through to the next rules that may select a new table.
The default rules refer to three tables: local for the local side
of the configured interfaces, main for the networks directly
reachable by those interfaces and default for networks reachable
through gateways. Unfortunately, there is no room between main
and default, so first let's remove the rule that selects routing
table main and then add it earlier:
ip -f inet rule del from all lookup main
ip -f inet rule add from all lookup main pref 32700
The default table has a confusing name, because there will be two default
tables soon. Go ahead and edit /etc/iproute2/rt_tables, renaming
the default table to
253 default-dynamic
and adding a new table:
1 default-static
That was easy, now let's add the rules themselves:
ip -f inet rule del from all lookup default-dynamic
ip -f inet rule add from all fwmark 1 lookup default-static pref 32766
ip -f inet rule add from all lookup default-dynamic pref 32767
That deletes the old default table rule and adds two
new rules: All packets marked with fwmark 1 will
be routed out the interface with the static IP and everything else
over the interface with the dynamic IP. The next section covers
how those marks are set.
What's still missing at this point are the actual routes in the
tables. The up script for the static IP interface needs these
lines:
echo 0 >/proc/sys/net/ipv4/conf/$1/rp_filter
/sbin/ip -f inet6 route replace 2000::/3 dev $1 table default-static
/sbin/ip -f inet route replace default dev $1 table default-static
First, it disables the reverse path unicast filter. With policy routing,
the routing policy no longer depends on the address, and rp_filter
only acts on the address. Then it sets the route for the interface for
both IPv4 and IPv6.
PPP interfaces, unlike ethernet interfaces, are created when a session starts and you can not configure a route for an interface that does not exist. For ethernet and persistent tun interfaces, you can do that. Should the interface ever go away, the table is empty and won't route packets, so they fall through to the next rule. You would not want them routed to the interface with the dynamic IP, so don't let the table get empty and use a lower priority static route to catch them:
ip -f inet route replace default dev lo metric 255 table default-static
If the interface exists and is up, its implicit metric 0 gives its
default route a higher priority. If it is down, packets are routed to
lo and trashed there, not leaving the site through
the wrong path.
The interface with the dynamic IP does not need that, because there is no further table.
Things work fine with this in its up script:
echo 0 >/proc/sys/net/ipv4/conf/ppp0/rp_filter
/sbin/ip -f inet route replace default dev ppp0 table default-dynamic
Describing the routing policy
At this point, tun0 would be idle, because no packets carry a
firewall mark, an annoyingly stupid name for a 32-bit number that can be
assigned to a packet for many reasons, firewalling just being one of them.
Although we could try to match all packets that need those marks set, the
result would be much work and still not perfect. Connection tracking assigns
all packets to a connection and just marking the connection saves much work
and delivers a great result.
Due to limitations in Linux, the routing layer has no clue of connection tracking and its connection marks. Instead if uses firewall marks, but both marks have nothing to do with each other and must not be confused. The trick is to assign connection marks to express the policy and finally store the connection mark of the connection a packet belongs to into the packets firewall mark.
Let's start assigning connection marks with initializing a few iptables and three environment variables for reability:
iptables -F
iptables -X
iptables -t nat -F
iptables -t nat -X
iptables -t mangle -F
iptables -t mangle -X
STATIF=tun0
STATMARK=1
DYNIF=ppp0
The first rules are obvious: Mark all connections from $STATIF
with $STATMARK, because we want responses to packets coming in
from that interface to be sent back the same way.
iptables -t mangle -A PREROUTING -i $STATIF -m state --state NEW \
-j CONNMARK --set-mark $STATMARK
iptables -t mangle -A PREROUTING -i $STATIF -m state --state ESTABLISHED \
-j CONNMARK --set-mark $STATMARK
iptables -t mangle -A PREROUTING -i $STATIF -m state --state RELATED \
-j CONNMARK --set-mark $STATMARK
About as obvious is that connections bound to the static IP as source should be treated just the same:
iptables -t mangle -A OUTPUT -s 217.197.85.202 -j CONNMARK --set-mark $STATMARK
Of course mail should be sent originating from the static IP in order to get accepted, so SMTP connections from my smarthost must be marked, too:
iptables -t mangle -A PREROUTING -s 10.128.0.3 -p tcp --dport smtp \
-m state --state NEW -j CONNMARK --set-mark $STATMARK
iptables -t mangle -A PREROUTING -s 10.128.0.3 -p tcp --dport smtp \
-m state --state ESTABLISHED -j CONNMARK --set-mark $STATMARK
iptables -t mangle -A PREROUTING -s 10.128.0.3 -p tcp --dport smtp \
-m state --state RELATED -j CONNMARK --set-mark $STATMARK
I guess you get the pattern now. Mark all connections that you want to use the interface with the static IP with a connection mark, no matter if they are incoming or outgoing. Once that is done, assign the connection mark to the firewall mark:
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
The second line is required, because packets originating from the router pass through different chains.
And while we are at it, although it belongs into different iptables chains, change the TCP MSS to the PMTU, because PPPoE means we have a smaller MTU than 1500 and sites running broken load balancers expect that the whole world will cure the symptoms for them, and that's what the world does:
iptables -A FORWARD -o ppp+ -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
NAT
For smaller installations, a single public address suffices by using destination NAT to route incoming connections to specific servers. This is needed to forward SMTP packets to my smarthost:
iptables -t nat -A PREROUTING -i $STATIF -p tcp --dport smtp -j DNAT --to-destination 10.128.0.3
Again, repeat such rules for all services you run. Finally, the packets leaving the site have to be NATed, too:
iptables -t nat -A POSTROUTING -o $STATIF -j MASQUERADE
iptables -t nat -A POSTROUTING -o $DYNIF -j MASQUERADE
Firewalling
There are many good documents explaining firewalling details, but not as many descriptions that target operability, so I will keep this section short by showing how my firewall is structured.
Very small installations know two sides: The internet before the firewall and the site behind. Larger sites introduce the concept of a DMZ, which is another network for servers behind the firewall with the advantage to restrict communication between those two networks behind the firewall as well. For some reason, people think it would be cool to put the DMZ next to the firewall, protecting servers by one firewall and users by two. DMZ is a good word if your users are armed and your admins are not, and great to sound cool. But how cool is a concept for 2 networks, if you can have 4095 VLANs, and how cool is one mistake in the outer firewall that exposes more of your valuable servers than you would like to?
Let's look at it from another perspective: Think of multiple networks, each connected with its own firewall to a backbone that connects all firewalls, with the internet happening to be one of those networks. Each packet has to pass through one firewall to leave its source network and through a second firewall to enter the destination network. With more smaller networks the amount of rules per network decreases to a manageable amount while giving fine granular control. A mistake in one rule, and even firewall admins make mistakes, requires a second identical mistake to cause a risk, because all packets pass two filters. Mistakes in the rules for leaving a network are even caught and can be logged by rules controlling entry to a network. Different firewalls may be administered by different departments according to their own policies.
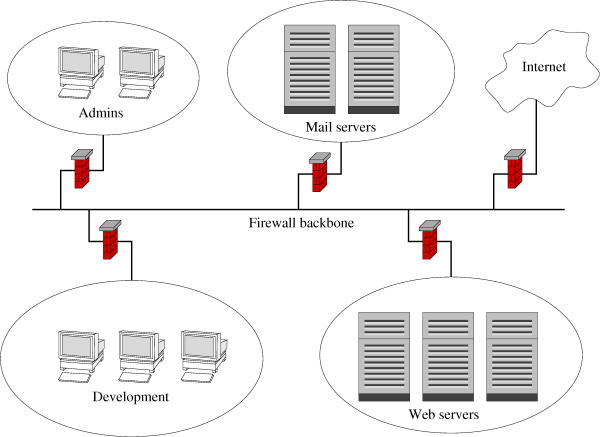
I consolidated all filters and the backbone into a single system, keeping
the structure. All packets in the FORWARD chain are first
sent to the SRC-FILTER, a dispatcher that distributes packets
depending on their source to chains for individual networks. If the
source filter for the network accepts the packet, it passes control
to the DST-FILTER, again a dispatcher that distributes
packets depending on their destination to chains for individual networks.
If the destination filter for the network accepts the packet, it jumps
to the ACCEPT target. All in all, you have two dispatchers
that are easy to understand and two chains per network, one to leave it
and one to enter it. Given 4095 VLANs and VLAN tagged interfaces, you
can have lots of networks and always tell exactly what the implemented
policy for a network is.
Start by defining the two dispatcher chains:
iptables -N DST-FILTER
iptables -N SRC-FILTER
Now defines chains for all networks, e.g. an network for printers and the like by creating a new chain and first allowing existing connections to be kept:
iptables -N SRC-MEDIA
iptables -A SRC-MEDIA -m state --state ESTABLISHED -j DST-FILTER
iptables -A SRC-MEDIA -m state --state RELATED -j DST-FILTER
Having access to the two DNS servers and to NTP is nice:
iptables -A SRC-MEDIA -p udp --dport 53 -d 10.128.0.2 -j DST-FILTER
iptables -A SRC-MEDIA -p tcp --dport 53 -d 10.128.0.2 -j DST-FILTER
iptables -A SRC-MEDIA -p udp --dport 53 -d 10.128.0.3 -j DST-FILTER
iptables -A SRC-MEDIA -p tcp --dport 53 -d 10.128.0.3 -j DST-FILTER
iptables -A SRC-MEDIA -p udp --dport 123 -d 10.128.0.2 -j DST-FILTER
And that's it:
iptables -A SRC-MEDIA -j LOG --log-level info --log-prefix "DENY SRC-MEDIA: "
iptables -A SRC-MEDIA -m limit --limit 2/s -j REJECT
iptables -A SRC-MEDIA -j DROP
All violations are logged, and if not too many, rejected, and silently dropped else.
Now the entry to that network is to be defined:
iptables -N DST-MEDIA
iptables -A DST-MEDIA -m state --state ESTABLISHED -j ACCEPT
iptables -A DST-MEDIA -m state --state RELATED -j ACCEPT
iptables -A DST-MEDIA -s 10.128.0.0/24 -j ACCEPT
iptables -A DST-MEDIA -s 10.160.0.5 -p tcp --dport ftp -j ACCEPT
iptables -A DST-MEDIA -j LOG --log-level info --log-prefix "DENY DST-MEDIA: "
iptables -A DST-MEDIA -m limit --limit 2/s -j REJECT
iptables -A DST-MEDIA -j DROP
All systems from one net have full access, but only a single system from a different net has FTP access to a single host. Guess which OS runs in each network. :)
Each network has an associated SRC- and DST- filter chain.
What remains are the dispatchers:
iptables -A SRC-FILTER -i $DYNIF -j SRC-INTERNET
iptables -A SRC-FILTER -i $STATIF -j SRC-INTERNET
iptables -A SRC-FILTER -i eth1.6 -j SRC-MEDIA
iptables -A SRC-FILTER -m limit --limit 2/s --limit-burst 20 -j LOG --log-level info --log-prefix "DENY SRC-FILTER: "
iptables -A SRC-FILTER -j DROP
If you see anything logged by this chain, you forgot a network. The destination dispatcher looks much the same:
iptables -A DST-FILTER -o $DYNIF -j DST-INTERNET
iptables -A DST-FILTER -o $STATIF -j DST-INTERNET
iptables -A DST-FILTER -o eth1.6 -j DST-MEDIA
iptables -A DST-FILTER -m limit --limit 2/s --limit-burst 20 -j LOG --log-level info --log-prefix "DENY DST-FILTER: "
iptables -A DST-FILTER -j DROP
Now start the source dispatcher and keep a last precaution against mistakes in it:
iptables -A FORWARD -j SRC-FILTER
iptables -A FORWARD -j LOG --log-level info --log-prefix "DROP BUGGY FORWARD: "
iptables -A FORWARD -j DROP
Finally, packets destined to and originating from the firewall need
filtering. It would be great if chains could be run as subchains,
acting on their result, to run the SRC-FILTER from
INPUT and DST-FILTER from OUTPUT,
but iptables does not allow that. So those need to be secured with a
single chain, violating the concept. At least the firewall itself only
needs administrative access and the ruleset will be tiny.
And now repeat all that for IPv6.